The Hidden Cost of Legacy ETL and Integration Tools
- Apr 26
- 9 min read
Updated: May 10
Why staying on aging data infrastructure costs more than you think — and what the path forward looks like.

There is a conversation that happens in a lot of organisations, usually triggered by something going wrong.
A pipeline fails and nobody knows how to fix it because the person who built it left two years ago. A system update breaks an integration that has been running quietly for four years. An auditor asks for a data lineage report and the team realises they cannot produce one. A new analytics requirement comes in and the answer is that it will take six months to build because the existing infrastructure cannot support it.
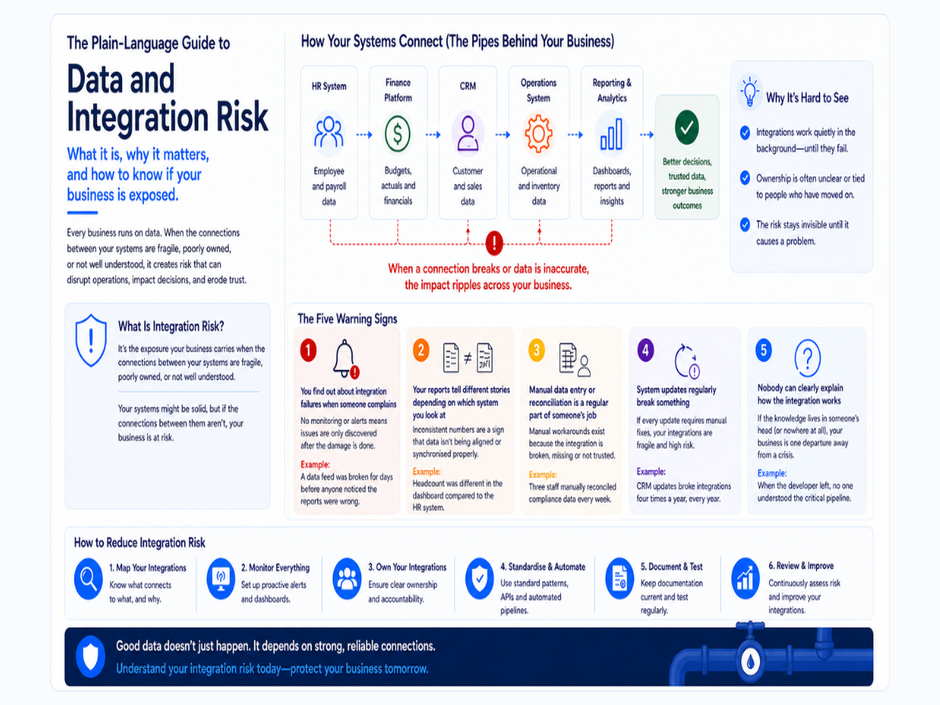
In each of these situations, the organisation faces the same uncomfortable realisation: the data and integration tools they built the business on have become a liability. The platform that served them well at one stage of growth is now slowing them down, creating operational exposure, and costing significantly more to maintain than anyone had accounted for.
This is the hidden cost of legacy ETL and integration tools. It does not show up on a single invoice. It accumulates quietly across operational disruptions, staff time, missed opportunities, and growing technical debt — until something forces the conversation.
This article explains what legacy ETL and integration tools actually cost, what the warning signs look like in practice, and what a realistic path forward looks like for organisations that are ready to modernise.
What Do We Mean by Legacy ETL and Integration Tools?
ETL stands for Extract, Transform, Load — the process of pulling data from a source system, transforming it into a useful format, and loading it into a destination. It is one of the foundational activities in any data environment.
Legacy ETL tools are the platforms and approaches that were built to do this job in an earlier era of enterprise technology. In Australian organisations, the most common ones we encounter are Oracle Data Integrator, Oracle stored procedures and job scripts, IBM DataStage, Informatica PowerCenter, and home-grown Python or shell scripts that have accumulated over many years.
On the integration side — connecting systems via APIs and messaging — legacy tools include Oracle ESB, IBM WebSphere Message Broker, TIBCO, Axway, and in more recent years, NiFi and MuleSoft when they have been deployed without proper governance and ownership.
None of these tools are inherently bad. Many of them were excellent choices at the time they were implemented. The problem is not the tools themselves — it is what happens to them over time when they are not actively owned, maintained, and evolved alongside the business they serve.
The Six Hidden Costs
1. The Key Person Dependency
The most immediate and underappreciated cost of legacy integration infrastructure is what happens when the person who built it leaves.
In most organisations, legacy ETL jobs and integration scripts were built by one or two people who understood the system intimately. Those people knew which jobs depended on which other jobs, what happened when a particular step failed, and which undocumented assumptions the whole thing rested on. When those people leave — and eventually they always do — that knowledge goes with them.
What remains is a set of scripts, jobs, and configurations that the remaining team can operate in normal conditions but cannot confidently modify, troubleshoot, or extend.
The organisation becomes fragile in ways it cannot fully see until something breaks.
A practical example: a university had a suite of Oracle Data Integrator jobs that had been built and maintained by a single senior developer over a period of eight years. When that developer retired, the team discovered that a significant portion of the job configurations existed only in that person's institutional memory. There was no documentation, no runbook, and no other team member who fully understood the dependency chain. Modifying anything became a significant risk exercise.
2. The Maintenance Tax
Legacy integration infrastructure requires continuous maintenance just to stay operational — and that maintenance cost grows over time as the surrounding technology landscape changes.
Every time a source system releases a new version, there is a risk that something in the integration layer breaks. Every time a database schema changes, ETL jobs that depend on that schema need to be updated. Every time an API authentication model changes, the integration code that handles it needs to be reworked.
In a well-governed modern environment, these changes are detected proactively, managed through a change control process, and deployed via automated pipelines. In a legacy environment, they are typically discovered reactively — when something breaks — and fixed manually, often under pressure.
That reactive maintenance cycle has a real cost. Developer time spent diagnosing and fixing breaks. Business disruption during the period when data is not flowing correctly. The compounding risk that a manual fix introduces a new problem while resolving the original one.
A practical example: a professional services firm running a suite of custom integration scripts found that every major release of their CRM platform required two to three days of developer time to identify and repair the integrations that had broken. This happened four times a year. Over three years that was the equivalent of roughly thirty developer days spent just keeping existing integrations alive — with no new capability delivered.
3. The Invisible Debt of Undocumented Flows
In most organisations with legacy integration infrastructure, nobody has a complete and accurate picture of what data flows exist, what they do, and what depends on them.
This is not because anyone was negligent. It is because integrations are typically built incrementally over many years, by different people, in response to specific business needs. Each individual integration made sense at the time. But the cumulative result is a landscape that nobody designed holistically and that no single person fully understands.
The cost of this shows up in several ways. When something breaks, diagnosis takes longer because the team has to rediscover how things are connected before they can fix anything. When a new requirement comes in, the team cannot confidently assess the impact of a change because they do not have a clear map of what depends on what. When an audit asks for data lineage, the team cannot provide it because nobody tracked it.
A practical example: a state government department undergoing an audit was asked to demonstrate how a specific compliance figure was calculated and where the underlying data came from. The data had passed through three different systems and two transformation steps before reaching the compliance report. Reconstructing that lineage took three weeks of manual investigation — time that would not have been needed in a governed, documented data environment.
4. The Scalability Ceiling
Legacy ETL tools and integration scripts were typically designed for the data volumes and processing requirements that existed when they were built. As businesses grow and data volumes increase, those tools hit a ceiling.
Jobs that used to run in two hours now take eight. Incremental loads that used to be manageable now require full reloads because the tool cannot handle change data capture at the required volume. New data sources cannot be onboarded without significant rework because the existing architecture was not designed to accommodate them.
This scalability ceiling does not just affect performance. It affects the organisation's ability to respond to new business requirements. When the data infrastructure cannot keep up with the business, the business slows down to match the infrastructure — or makes do with incomplete information.
A practical example: a mining company's workforce analytics platform had been built on a legacy ETL tool that performed well when processing data for three hundred workers at a single site. As the company expanded to eight sites and four thousand workers, the nightly processing jobs began running into the following day's window. By the time the analytics team arrived in the morning, the previous day's data had not finished loading. Operational decisions were being made on thirty-six-hour-old information.
5. The Compliance and Governance Gap
Modern regulatory environments in education, government, financial services, and mining require organisations to demonstrate not just what their data says but where it came from and how it was handled.
Legacy ETL tools were not built with this requirement in mind. They typically provide limited or no lineage tracking, inconsistent audit logging, and no centralised governance layer. Meeting modern compliance obligations with legacy infrastructure requires significant manual effort — and still produces an incomplete result.
As regulatory scrutiny increases, this gap becomes more expensive to manage and riskier to ignore.
6. The Opportunity Cost of Standing Still
This is the hardest cost to quantify but arguably the most significant. Every hour your data team spends maintaining legacy infrastructure is an hour not spent building new capability.
Advanced analytics, AI readiness, real-time reporting, self-service data access for business teams — all of these require a solid, governed data foundation to build on. Organisations running on legacy ETL and integration infrastructure cannot build meaningfully on top of it. They are spending their capacity keeping the lights on rather than moving forward.
This opportunity cost is compounding. Every month spent maintaining a legacy environment is another month of competitive ground lost to organisations that have already modernised and are now building AI and analytics capabilities on top of a clean, governed platform.
The AI Dimension
The opportunity cost of legacy infrastructure has taken on a new dimension with the rise of AI.
Every credible AI initiative — predictive workforce analytics, automated compliance reporting, natural language interfaces for business data, machine learning models for operational optimisation — requires clean, governed, well-structured data to work from. Legacy ETL environments, with their undocumented flows, inconsistent transformations, and absence of lineage tracking, cannot support AI workloads reliably.
Organisations that want to use AI meaningfully in the next two to three years need to have resolved their data infrastructure debt now. The organisations investing in modern data platforms today — Azure Databricks Lakehouse, Unity Catalog governance, Medallion architecture, CI/CD-governed pipelines — are building the foundation on which AI capability will run. Those still maintaining legacy ETL environments will find themselves unable to participate meaningfully in that next wave without a significant and disruptive catch-up investment.
What the Path Forward Looks Like
The prospect of modernising a legacy data and integration environment is daunting for most organisations. The temptation is to avoid it until circumstances force the issue. But in our experience, phased modernisation on your own terms is significantly less disruptive and less expensive than reactive modernisation after something has gone seriously wrong.
Here is what a realistic path forward typically looks like.
Start with an honest assessment. Before anything else, you need a clear picture of what you have — what integrations exist, which are business-critical, how fragile they are, and what the dependencies look like. This is the foundation that everything else is built on. Without it, any modernisation effort risks solving the wrong problems first.
Establish the target platform. In most cases for Australian mid-sized organisations, this means establishing an Azure Databricks Lakehouse as the central data platform, with Azure integration services handling the connectivity layer. The target architecture should be decided before any migration work begins, so that each migration moves toward a coherent end state rather than creating a new version of the same fragmentation.
Migrate in priority order. Not everything needs to move at once. The right approach is to identify the highest-risk and most business-critical integrations first — the ones where failure causes the most disruption — and migrate those in the early phases. Lower-risk, lower-complexity integrations follow in subsequent phases. This approach delivers early risk reduction while keeping the migration manageable.
Decommission as you go. One of the most important disciplines in a migration program is actively decommissioning legacy components once their replacement is validated and stable. Organisations that migrate without decommissioning end up running two environments in parallel indefinitely — which doubles the maintenance burden rather than reducing it.
Own the new environment properly. The single biggest lesson from organisations that have successfully modernised is that the new environment needs clear ownership from day one. This means documented pipelines, governed infrastructure, active monitoring, and a team — internal or external — that is accountable for keeping it running and evolving it as requirements change. Without ongoing ownership, the new environment will accumulate the same technical debt as the old one, just more slowly.
A Real-World Example
A major Australian university had built years of data operations on a combination of Oracle Data Integrator, Oracle stored procedures, NiFi, Qlik Replicate, Oracle ESB, and Axway. The stack had grown incrementally over a decade as different systems were added and different integration approaches were adopted.
By the time the decision to modernise was made, the environment had several of the characteristics described in this article — key person dependencies, undocumented flows, a growing maintenance burden with each new system release, a compliance reporting process requiring significant manual effort, and a team spending more time keeping things running than building new capability.
The modernisation program moved to a unified Azure platform — Azure APIM and Logic Apps replacing the ESB and Axway layer, Azure Data Factory and Azure Databricks replacing the Oracle ETL and NiFi layer, and a governed Databricks Lakehouse as the central platform. The migration is progressing in priority order, with the core platform now operational and pipelines being validated and transitioned systematically.
The outcome is not just a technology upgrade. It is a governed, documented, monitored environment with clear ownership — one that the university's internal team can understand, operate, and evolve with confidence. And critically, it is a platform on which AI and advanced analytics workloads can be built when the organisation is ready to take that next step.
Is Your Organisation Ready to Have This Conversation?
You do not need to have a crisis to justify looking at this question seriously. If your organisation is running on integration infrastructure that is more than five years old, that is not actively maintained, or that only one or two people fully understand — the conversation is worth having now rather than after something forces it.
The first step is understanding where you actually are. That is what our Data and Integration Risk Assessment is designed to provide — a clear, evidence-based picture of your current environment, the areas carrying the most exposure, and a prioritised path forward.
Cypher Agency is a boutique data and integration engineering firm helping mid-sized Australian businesses build reliable, governed data and integration environments — without the cost of building an internal team.

Comments